Welcome to everyone that signed up during the past week! Today's post continues our ongoing series on customer lifetime value ("CLV"). Here are the previous three posts:
Our focus will now shift to customer lifetime — the backbone of any CLV model. To start, let's revisit our first post for a definition of customer lifetime and a few key points.
"Customer lifetime" is an estimate of how many times a customer will buy your product over time. For subscription products, we want to know how long someone will remain a paying subscriber before they cancel.
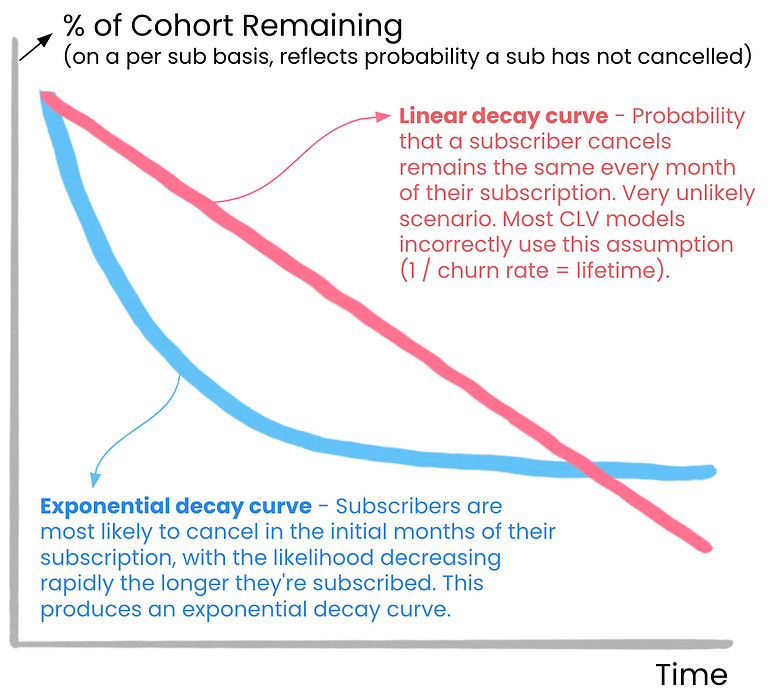
Usually, subscribers are most likely to cancel earlier in their subscription. And the likelihood of canceling decreases rapidly the longer someone stays subscribed.
In other words, the probability that a paying subscriber will cancel decreases exponentially, not linearly, over time. We can use these cancel rates to produce a customer decay curve. The curve shows the likelihood that someone remains subscribed over time.
The shape of the subscriber decay curve is almost always exponential, not linear.
The customer decay curve is often the most influential driver in our CLV model. To guide our discussion, we will explore two frequently-encountered scenarios for establishing our decay curve assumption:
You haven't launched your product yet and don't have any data.
You've launched and want to use retention data to update your decay curve.
I tried to pack both into a single post but tip-toed past a reasonable word count. The post below will be the first in a 2-part mini-series on setting your decay curve assumption.
The decay curve assumption is towards the bottom of the "CLV Model (2-yr)" tab (line 27), highlighted and surrounded by the thick border in the image below. There's also a visual of the decay curve assumption in the left line chart (“Customer Lifetime Projection”), which can help us grasp how the curve moves as we adjust assumptions.
2-year CLV Model
We've had a few readers ask how far the decay curve forecast should extend, or what the maximum customer lifetime should be. Like any model, we must end our CLV forecast at some point. The maximum customer lifetime can have a material impact on the output; while there are guardrails for deciding when to end it, ultimately, it's a bit subjective. We'll return to this in a few posts — for now, let's use a 2-year maximum customer lifetime.
Let's also bring back Big Dean to help us walk through our first scenario: our budding entrepreneur is back in the pre-launch planning phase and has yet to learn how well he'll retain his paying subscribers.
Pre-launch with no data
Many operators will face the challenge of having limited or no data, especially early on. For those just starting, being resourceful can go a long way. Even just a few reliable data points can help guide initial assumptions and provide context as retention data comes in.
The best approach to picking up valuable data points is usually to ask folks working on similar products.1 If you're using a platform (e.g., Patreon, Substack, Stripe), it might be worth asking for guidance. There are also 3rd party services that provide data on paid retention and decay curves, like our friends at Antenna.
Keep in mind there can be a wide variance in retention across different products, which makes it challenging to set initial retention assumptions. Even if we're lucky to find some solid data points, we'll still likely have to choose from a wide range of possibilities for the initial decay curve assumption. Early on, the goal is not precision — we're only trying to get in the right ballpark.
Also, with any assumption, it's always nice to be pleasantly surprised. It's usually prudent to err towards more conservative assumptions for any performance metric, especially with limited or no data.
Big Dean is hungry for data. He starts by reaching out to other Food & Drink newsletters in Substack's Discover section and restauranteur-operated media companies across the internet. Most of the folks he talks to are incredibly friendly and helpful. The discussions lead to a handful of useful data points, as well as tips on best practices and other insights.
Through these conversations and further research, Big Dean thinks he'll be able to retain 50% to 70% of paid subscribers after the first year. To be conservative, he decides to model the initial curve towards 50% retained after the first year.
We use a power function in the model to form the decay curve.2 The key driver in the model is the exponent in the power function (here’s a link to the cell in the Google Sheet). Big Dean adjusts and fine-tunes this driver, bending the curve toward 50% of paid subs remaining after 12 months (which ends up being a constant power of -0.28).3
Fine-tuning the decay curve assumption.
We're in business! Now we have some initial expectations for paid retention rates during our first year. Based on the curve, we can set a loose target of retaining 82% of our paying subs after the 1st payment and 62% after the 6th payment.
We also have our first glimpse into our forecasted cash earnings over time. Based on our subscriber economics and decay curve assumptions, for the average subscriber, we expect to make $38 after six months, $65 after the first year, and $110 after two years.
But there are a few caveats. First, it's worth noting that there will likely be a lot of noise in the data early on, especially with a lower volume of subscription data. In the first months, it may be better to focus on more engagement-oriented metrics or qualitative feedback.
Also, don't fool yourself into thinking this is a crystal ball. We're unlikely to generate accurate predictions without using data to inform our forecast. We're only trying to get in the right ballpark and lay a solid foundation for when we have data (which is precisely where we'll pick up our next post).
That’s it for this week — what do you think? If you’re considering launching a subscription product, how did this post impact your thinking? If you’ve already launched, how would this have helped you back in the pre-launch days?
Tune in next week when we cover how to get retention data from Stripe, transform it into a decay curve, and then use it to update our CLV model.
Thanks for reading, Reid
If you want to show that you value this type of work, please consider a paid subscription to Growth Croissant 🥐.
In a power function, we take a variable and raise it by a constant power. In our model, the variable is time, expressed in months to map to monthly subscriptions. The constant power is the declining likelihood that a sub cancels relative to the passage of time.
I'm laughably far from a mathematician. The approach I'm describing is country miles from the most sophisticated approach. I'm attempting to guide us through a process I can do, which means anyone can do it. But by all means, please use this as a launchpad and build in sophistication that leads to more accuracy, and let us know how we can improve the model in the comments!